


畜牧兽医学报 ›› 2025, Vol. 56 ›› Issue (9): 4410-4421.doi: 10.11843/j.issn.0366-6964.2025.09.023
骞里1( ), 梁忙1, 邓天宇1,2, 杜丽丽1, 李柯安宁1, 邱诗元1, 薛青青1,3, 张路培1, 高雪1, 徐凌洋1, 郑彩宏1, 李俊雅1, 高会江1,*()
), 梁忙1, 邓天宇1,2, 杜丽丽1, 李柯安宁1, 邱诗元1, 薛青青1,3, 张路培1, 高雪1, 徐凌洋1, 郑彩宏1, 李俊雅1, 高会江1,*()
收稿日期:2025-02-26
出版日期:2025-09-23
发布日期:2025-09-30
通讯作者:
高会江
E-mail:pbli0201@163.com;gaohuijiang@caas.cn
作者简介:骞里(2000-),男,陕西西安人,硕士生,主要从事深度学习基因组选择方法研究,E-mail:pbli0201@163.com
基金资助:
QIAN Li1(), LIANG Mang1, DENG Tianyu1,2, DU Lili1, LI Keanning1, QIU Shiyuan1, XUE Qingqing1,3, ZHANG Lupei1, GAO Xue1, XU Lingyang1, ZHENG Caihong1, LI Junya1, GAO Huijiang1,*()
Received:2025-02-26
Online:2025-09-23
Published:2025-09-30
Contact:
GAO Huijiang
E-mail:pbli0201@163.com;gaohuijiang@caas.cn
摘要:
为进一步探索传统线性回归模型难以捕捉基因型与表型之间复杂关系的不足, 本研究旨在利用机器学习整合组学数据提升基因组预测的准确性。本研究基于具有基因型与转录组数据的数据集:1)华西牛数据集涉及宰前活重、胴体重和净肉重3个主要经济性状;2)水稻数据集包含单株产量、每穗粒数和千粒重3个农艺性状。采用五折交叉验证,以皮尔逊相关系数评估育种值估计的准确性。首先比较了基于单一组学数据作为输入时的预测表现,随后基于自编码器构建隐含矩阵作为关系矩阵用于模型建模。结果表明,使用转录组数据替代基因组数据作为输入可以提升模型的预测能力。在水稻和华西牛数据集分别提高了44.2%和27.4%,进一步地,将隐含矩阵用于建模后,模型预测准确性相较基因组关系矩阵在水稻和华西牛中分别提升了4.10%和6.81%。相关性分析表明,隐含矩阵与原始组学数据之间存在较强的非线性关系。将转录组作为模型输入,结合自编码器构建的关系矩阵,可有效提升选种选育的准确性,为育种工作的持续改进提供参考依据。
中图分类号:
骞里, 梁忙, 邓天宇, 杜丽丽, 李柯安宁, 邱诗元, 薛青青, 张路培, 高雪, 徐凌洋, 郑彩宏, 李俊雅, 高会江. 基于自编码器整合转录组数据提升基因组预测的准确性[J]. 畜牧兽医学报, 2025, 56(9): 4410-4421.
QIAN Li, LIANG Mang, DENG Tianyu, DU Lili, LI Keanning, QIU Shiyuan, XUE Qingqing, ZHANG Lupei, GAO Xue, XU Lingyang, ZHENG Caihong, LI Junya, GAO Huijiang. Improving Genomic Prediction Accuracy via Auto-encoder-based Compression of Transcriptome Data[J]. Acta Veterinaria et Zootechnica Sinica, 2025, 56(9): 4410-4421.
表 1
华西牛和水稻数据集中KRR模型的架构及相关参数"
| 数据集 Dataset | 性状 Trait | 输入数据类型 Input data type | 模型 Model | α Alpha | λ Lambda | 核函数 Kernel |
| 华西牛 Huaxi cattle | 宰前活重 Live weight | 基因组Genome | KRR_G | 0.5 | 0.1 | rbf |
| 转录组Transcriptome | KRR_T | 0.5 | 0.1 | rbf | ||
| 胴体重 Carcass weight | 基因组Genome | KRR_G | 0.5 | 0.1 | rbf | |
| 转录组Transcriptome | KRR_T | 0.5 | 0.1 | rbf | ||
| 净肉重 Net meat weight | 基因组Genome | KRR_G | 0.5 | 0.01 | rbf | |
| 转录组Transcriptome | KRR_T | 0.4 | 0.1 | rbf | ||
| 水稻 Rice | 单株产量 Yield | 基因组Genome | KRR_G | 1.0 | default | rbf |
| 转录组Transcriptome | KRR_T | 1.0 | default | rbf | ||
| 每穗粒数 Grain | 基因组Genome | KRR_G | 1.0 | default | rbf | |
| 转录组Transcriptome | KRR_T | 1.0 | default | rbf | ||
| 千粒重 KGW | 基因组Genome | KRR_G | 1.0 | default | rbf | |
| 转录组Transcriptome | KRR_T | 1.0 | default | rbf |
表 2
ANN的模型结构和参数"
| 数据集 Dataset | 性状 Trait | 模型 Model | 学习率 Learning rate | 训练轮次 Epoch | 批大小 Batch size | 各层神经元数 Neurons | 激活函数 Activation |
| 水稻 Rice | 单株产量Yield | ANN_G | 0.000 1 | 50 | 8 | (128,16) | ReLU |
| ANN_T | 0.000 5 | 100 | 6 | (256,32) | ReLU | ||
| 每穗粒数Grain | ANN_G | 0.001 | 100 | 6 | (128,16) | ReLU | |
| ANN_T | 0.000 1 | 50 | 23 | (128,16) | ReLU | ||
| 千粒重KGW | ANN_G | 0.001 | 50 | 6 | (128,16) | ReLU | |
| ANN_T | 0.001 | 50 | 6 | (128,16) | null | ||
| 华西牛 Huaxi cattle | 宰前活重Live weight | ANN_G | 0.001 | 50 | 8 | (128,16) | ReLU |
| ANN_T | 0.001 | 50 | 8 | (128,16) | ReLU | ||
| 胴体重Carcass weight | ANN_G | 0.001 | 50 | 8 | (128,16) | ReLU | |
| ANN_T | 0.001 | 50 | 8 | (128,16) | ReLU | ||
| 净肉重Net meat weight | ANN_G | 0.001 | 50 | 8 | (128,16) | ReLU | |
| ANN_T | 0.001 | 50 | 6 | (128,16) | ReLU |
表 3
自动编码器的模型结构"
| 模块 Block | 输入维度 Input dimension | 隐藏维度 Hidden dimension | 输出维度 Output dimension | 训练轮次 Epoch | 批大小 Batch size | 学习率 Learning rate |
| 编码器Encoder | 218/210 | 128 | 64 | 50 | 8 | 0.1 |
| 解码器Decoder | 64 | 128 | 218/210 | 50 | 8 | 0.1 |
表 4
KRR_LM模型架构及参数"
| 数据集 Dataset | 性状 Trait | α Alpha | λ Lambda | 核函数 Kernel |
| 水稻 Rice | 单株产量Yield | 0.3 | 0.001 | rbf |
| 每穗粒数Grain | 0.3 | 0.001 | rbf | |
| 千粒重KGW | 0.3 | 0.001 | rbf | |
| 华西牛 Huaxi cattle | 宰前活重Live weight | 0.4 | 0.2 | rbf |
| 胴体重Carcass weight | 0.4 | 0.2 | rbf | |
| 净肉重Net meat weight | 5 | 0.01 | rbf |
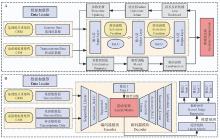
图 1
ANN和KRR_LM算法拓扑结构示意图"

表 5
表型数据的基本描述性统计信息和遗传力估计"
| 数据集 Dataset | 性状 Trait | 个体数 Count | 遗传力 Heritability | 表型平均值 Mean | 最小值 Minimum | 中位数 Median | 最大值 Maximum |
| 水稻 Rice | 单株产量Yield | 210 | 0.74 | 25.88±4.40 | 9.96 | 26.35 | 36.99 |
| 每穗粒数Grain | 210 | 0.91 | 99.42±19.20 | 50.18 | 98.59 | 149.33 | |
| 千粒重KGW | 210 | 0.97 | 24.41±2.51 | 18.03 | 24.51 | 29.92 | |
| 华西牛 Huaxi cattle | 宰前活重Live weight | 218 | 0.44 | 692.68±69.81 | 514.40 | 684.00 | 868.60 |
| 胴体重Carcass weight | 218 | 0.34 | 379.95±40.12 | 268.30 | 375.40 | 476.20 | |
| 净肉重Net meat weight | 148 | 0.49 | 324.88±37.27 | 229.30 | 321.40 | 412.10 |

图 2
华西牛与水稻数据集各性状的分布及正态性检验"
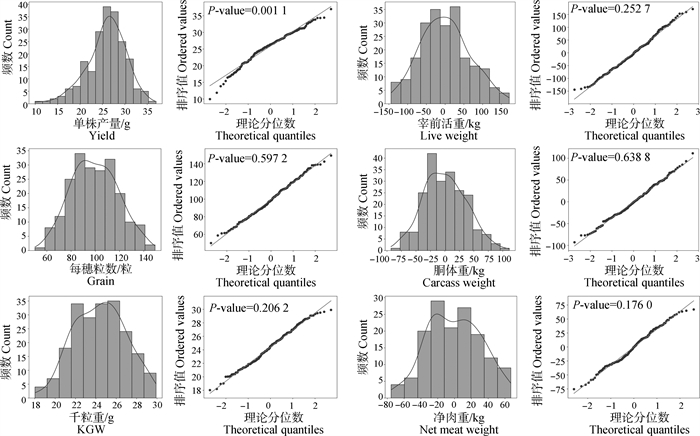
图 3
华西牛和水稻数据集中基于单一组学数据作为输入的各模型预测准确性比较"
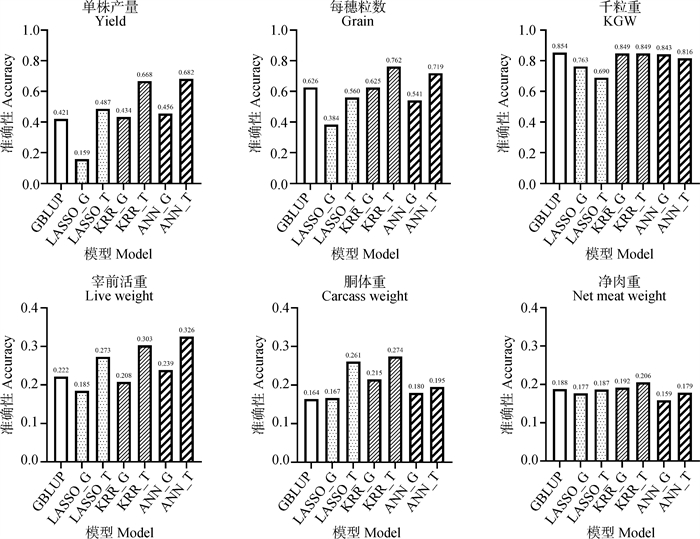
表 6
在同一模型中使用转录组数据作为输入相较基因组数据作为输入的模型性能提升比例"
| 数据集 Dataset | 性状 Trait | 模型/% Lasso | 模型/% KRR | 模型/% ANN | 平均预测准确性/% Mean prediction accuracy |
| 水稻 Rice | 单株产量Yield | 206.3 | 53.9 | 49.6 | 103.3 |
| 每穗粒数Grain | 45.8 | 21.9 | 32.9 | 33.5 | |
| 千粒重KGM | -9.6 | 0.0 | -3.2 | -4.3 | |
| 平均预测准确性Mean prediction accuracy | 80.8 | 25.3 | 26.4 | 44.2 | |
| 华西牛 Huaxi cattle | 宰前活重Live weight | 47.6 | 45.6 | 36.4 | 43.2 |
| 胴体重Carcass weight | 56.3 | 27.4 | 8.3 | 30.7 | |
| 净肉重Net meat weight | 5.5 | 7.3 | 12.6 | 8.5 | |
| 平均预测准确性Mean prediction accuracy | 36.5 | 26.8 | 19.1 | 27.4 |
表 7
在华西牛和水稻数据集中KRR_LM模型与其它模型的预测性能比较"
| 数据集 Dataset | 性状 Trait | 模型 GBLUP | 模型 KRR_G | 模型 ANN_G | 模型 KRR_LM |
| 水稻 Rice | 单株产量Yield | 0.421 | 0.434 | 0.456 | 0.483 |
| 每穗粒数Grain | 0.626 | 0.625 | 0.541 | 0.641 | |
| 千粒重KGW | 0.854 | 0.849 | 0.843 | 0.857 | |
| 平均预测准确性Mean prediction accuracy | 0.634 | 0.636 | 0.613 | 0.660 | |
| 华西牛 Huaxi cattle | 宰前活重Live weight | 0.222 | 0.185 | 0.239 | 0.216 |
| 胴体重Carcass weight | 0.164 | 0.167 | 0.180 | 0.205 | |
| 净肉重Net meat weght | 0.188 | 0.154 | 0.159 | 0.191 | |
| 平均预测准确性Mean prediction accuracy | 0.191 | 0.169 | 0.193 | 0.204 |

图 4
华西牛数据集和水稻数据集中各矩阵相关系数热图"

| 1 |
SCHAEFFER L R . Strategy for applying genome-wide selection in dairy cattle[J]. J Anim Breed Genet, 2006, 123, 218- 223.
doi: 10.1111/j.1439-0388.2006.00595.x |
| 2 |
WIGGANS G R , CARRILLO J A . Genomic selection in United States dairy cattle[J]. Front Genet, 2022, 13, 994466.
doi: 10.3389/fgene.2022.994466 |
| 3 | GARCÍA-RUIZ A , COLE J B , VANRADEN P M , et al. Changes in genetic selection differentials and generation intervals in US Holstein dairy cattle as a result of genomic selection[J]. Proc Natl Acad Sci U S A, 2016, 113, E3995- E4004. |
| 4 |
WIGGANS G R , COLE J B , HUBBARD S M , et al. Genomic selection in dairy cattle: The USDA experience[J]. Annu Rev Anim Biosci, 2017, 5, 309- 327.
doi: 10.1146/annurev-animal-021815-111422 |
| 5 | CAMPOS G S , CARDOSO F F , GOMES C C G , et al. Development of genomic predictions for Angus cattle in Brazil incorporating genotypes from related American sires[J]. J Anim Sci, 2022, 1, 100. |
| 6 |
ZHANG Z , LIU J , DING X , et al. Best linear unbiased prediction of genomic breeding values using a trait-specific marker-derived relationship matrix[J]. PLoS One, 2010, 5 (9): E12648.
doi: 10.1371/journal.pone.0012648 |
| 7 |
EDWARDS S M , S∅RENSEN I F , SARUP P , et al. Genomic prediction for quantitative traits is improved by mapping variants to gene ontology categories in Drosophila melanogaster[J]. Genetics, 2016, 203, 1871- 1883.
doi: 10.1534/genetics.116.187161 |
| 8 |
MEUWISSEN T , EIKJE L S , GJUVSLAND A B . GWABLUP: genome-wide association assisted best linear unbiased prediction of genetic values[J]. Genet Sel Evol, 2024, 56, 17.
doi: 10.1186/s12711-024-00881-y |
| 9 | LOPES M S , BOVENHUIS H , VAN SON M , et al. Using markers with large effect in genetic and genomic predictions[J]. J Anim Sci, 2017, 95, 59- 71. |
| 10 |
MISZTAL I , LEGARRA A , AGUILAR I . Computing procedures for genetic evaluation including phenotypic, full pedigree, and genomic information[J]. J Dairy Sci, 2009, 92, 4648- 4655.
doi: 10.3168/jds.2009-2064 |
| 11 |
MNTYSAARI E A , EVANS R D , STRANDN I . Efficient single-step genomic evaluation for a multibreed beef cattle population having many genotyped animals[J]. J Anim Sci, 2017, 95, 4728- 4737.
doi: 10.2527/jas2017.1912 |
| 12 |
XU Y , ZHANG Y , CUI Y , et al. GA-GBLUP: leveraging the genetic algorithm to improve the predictability of genomic selection[J]. Brief Bioinform, 2024, 25 (5): 385.
doi: 10.1093/bib/bbae385 |
| 13 |
WU B , XIONG H , ZHUO L , et al. Multi-view BLUP: a promising solution for post-omics data integrative prediction[J]. J Genet Genomics, 2025, 52, 839- 847.
doi: 10.1016/j.jgg.2024.11.017 |
| 14 |
GESTEIRO N , MALVAR R A , BUTRN A , et al. Genome-wide association study and genomic predictions for hydroxycinnamate concentrations in maize stover[J]. J Agric Food Chem, 2025, 73, 2289- 2298.
doi: 10.1021/acs.jafc.4c07467 |
| 15 |
XU H , WANG Z , WANG F , et al. Genome-wide association study and genomic selection of spike-related traits in bread wheat[J]. Theor Appl Genet, 2024, 137, 131.
doi: 10.1007/s00122-024-04640-x |
| 16 |
XU R , YANG Q , LIU Z , et al. Genome-wide association analysis and genomic prediction of salt tolerance trait in soybean germplasm[J]. Front Plant Sci, 2024, 15, 1494551.
doi: 10.3389/fpls.2024.1494551 |
| 17 | LIU K , YIN Y , WANG B , et al. Integrating significant SNPs identified by GWAS for genomic prediction of the number of ribs and carcass length in Suhuai pigs[J]. Animals (Basel), 2025, 15 (3): 412. |
| 18 |
ZHAO Z , NIU Q , WU T , et al. Comparative analysis of genomic prediction for production traits using genomic annotation and a genome-wide association study at sequencing levels in beef cattle[J]. Agriculture, 2024, 14, 2255.
doi: 10.3390/agriculture14122255 |
| 19 | TU T C , LIN C J , LIU M C , et al. Genomic prediction and genome-wide association study for growth-related traits in Taiwan Country chicken[J]. Animals (Basel), 2025, 15 (3): 376. |
| 20 |
CRICK F . Central dogma of molecular biology[J]. Nature, 1970, 227, 561- 563.
doi: 10.1038/227561a0 |
| 21 |
DE LOS CAMPOS G , HICKEY J M , PON WONG R , et al. Whole-genome regression and prediction methods applied to plant and animal breeding[J]. Genetics, 2013, 193, 327- 345.
doi: 10.1534/genetics.112.143313 |
| 22 |
KANG M , KO E , MERSHA T B . A roadmap for multi-omics data integration using deep learning[J]. Brief Bioinform, 2022, 23 (1): bbab454.
doi: 10.1093/bib/bbab454 |
| 23 |
FRISCH M , THIEMANN A , FU J , et al. Transcriptome-based distance measures for grouping of germplasm and prediction of hybrid performance in maize[J]. Theor Appl Genet, 2010, 120, 441- 450.
doi: 10.1007/s00122-009-1204-1 |
| 24 |
ZENKE-PHILIPPI C , THIEMANN A , SEIFERT F , et al. Prediction of hybrid performance in maize with a ridge regression model employed to DNA markers and mRNA transcription profiles[J]. BMC Genomics, 2016, 17, 262.
doi: 10.1186/s12864-016-2580-y |
| 25 | RITCHIE M D , HOLZINGER E R , LI R , et al. Methods of integrating data to uncover genotype-phenotype interactions[J]. Nat Rev Genet, 2015, 16, 85- 97. |
| 26 |
ZHU J , SOVA P , XU Q , et al. Stitching together multiple data dimensions reveals interacting metabolomic and transcriptomic networks that modulate cell regulation[J]. PLoS Biol, 2012, 10, e1001301.
doi: 10.1371/journal.pbio.1001301 |
| 27 |
AN B , LIANG M , CHANG T , et al. KCRR: a nonlinear machine learning with a modified genomic similarity matrix improved the genomic prediction efficiency[J]. Brief Bioinform, 2021, 22 (6): bbab132.
doi: 10.1093/bib/bbab132 |
| 28 |
LI M , HALL T , MACHUGH D E , et al. KPRR: a novel machine learning approach for effectively capturing nonadditive effects in genomic prediction[J]. Brief Bioinform, 2024, 26 (1): bbae683.
doi: 10.1093/bib/bbae683 |
| 29 | WANG J , ZONG W , SHI L , et al. Using mixed kernel support vector machine to improve the predictive accuracy of genome selection[J]. Journal of Integrative Agriculture, 2024, 3, 083. |
| 30 | THORSRUD J A , EVANS K M , QUIGLEY K C , et al. Performance comparison of genomic best linear unbiased prediction and four machine learning models for estimating genomic breeding values in working dogs[J]. Animals (Basel), 2025, 15 (3): 408. |
| 31 |
VAN DER LAAN L , PARMLEY K , SAADATI M , et al. Genomic and phenomic prediction for soybean seed yield, protein, and oil[J]. Plant Genome, 2025, 18, e70002.
doi: 10.1002/tpg2.70002 |
| 32 | HANSEN P B , RUUD A K , DE LOS CAMPOS G , et al. Integration of DNA methylation and transcriptome data improves complex trait prediction in Hordeum vulgare[J]. Plants (Basel), 2022, 11 (17): 2190. |
| 33 |
KNOCH D , WERNER C R , MEYER R C , et al. Multi-omics-based prediction of hybrid performance in canola[J]. Theor Appl Genet, 2021, 134, 1147- 1165.
doi: 10.1007/s00122-020-03759-x |
| 34 |
XU F , CHE Z , QIAO J , et al. Integrating gene expression data into single-step method (ssBLUP) improves genomic prediction accuracy for complex traits of Duroc×Erhualian F(2) pig population[J]. Curr Issues Mol Biol,, 2024, 46, 13713- 13724.
doi: 10.3390/cimb46120819 |
| 35 |
ZHAO L , TANG P , LUO J , et al. Genomic prediction with NetGP based on gene network and multi-omics data in plants[J]. Plant Biotechnol J, 2025, 23, 1190- 1201.
doi: 10.1111/pbi.14577 |
| 36 |
WANG K , ABID M A , RASHEED A , et al. DNNGP, a deep neural network-based method for genomic prediction using multi-omics data in plants[J]. Mol Plant, 2023, 16, 279- 293.
doi: 10.1016/j.molp.2022.11.004 |
| 37 |
MA W , QIU Z , SONG J , et al. A deep convolutional neural network approach for predicting phenotypes from genotypes[J]. Planta, 2018, 248, 1307- 1318.
doi: 10.1007/s00425-018-2976-9 |
| 38 |
WU C , ZHANG Y , YING Z , et al. A transformer-based genomic prediction method fused with knowledge-guided module[J]. Brief Bioinform, 2023, 25 (1): bbad438.
doi: 10.1093/bib/bbad438 |
| 39 |
ZOU Q , TAI S , YUAN Q , et al. Large-scale crop dataset and deep learning-based multi-modal fusion framework for more accurate G×E genomic prediction[J]. Computers and Electronics in Agriculture, 2025, 230, 109833.
doi: 10.1016/j.compag.2024.109833 |
| 40 |
HUA J , XING Y , WU W , et al. Single-locus heterotic effects and dominance by dominance interactions can adequately explain the genetic basis of heterosis in an elite rice hybrid[J]. Proc Natl Acad Sci U S A, 2003, 100, 2574- 2579.
doi: 10.1073/pnas.0437907100 |
| 41 |
YU H , XIE W , WANG J , et al. Gains in QTL detection using an ultra-high density SNP map based on population sequencing relative to traditional RFLP/SSR markers[J]. PLoS One, 2011, 6, e17595.
doi: 10.1371/journal.pone.0017595 |
| 42 |
WANG J , YU H , WENG X , et al. An expression quantitative trait loci-guided co-expression analysis for constructing regulatory network using a rice recombinant inbred line population[J]. J Exp Bot, 2014, 65, 1069- 1079.
doi: 10.1093/jxb/ert464 |
| 43 |
HU X , XIE W , WU C , et al. A directed learning strategy integrating multiple omic data improves genomic prediction[J]. Plant Biotechnol J, 2019, 17, 2011- 2020.
doi: 10.1111/pbi.13117 |
| 44 |
HUMPHREYS R K , PUTH M T , NEUHUSER M , et al. Underestimation of Pearson 's product moment correlation statistic[J]. Oecologia, 2019, 189, 1- 7.
doi: 10.1007/s00442-018-4233-0 |
| 45 |
TRIPATHI Y M , CHATLA S B , CHANG Y I , et al. A nonlinear correlation measure with applications to gene expression data[J]. PLoS One, 2022, 17, e0270270.
doi: 10.1371/journal.pone.0270270 |
| 46 |
WANG X , SHI S , WANG G , et al. Using machine learning to improve the accuracy of genomic prediction of reproduction traits in pigs[J]. J Anim Sci Biotechnol, 2022, 13, 60.
doi: 10.1186/s40104-022-00708-0 |
| 47 |
GONDRO C , VAN DER WERF J , HAYES B . Genome-wide association studies and genomic prediction[M]. Springer, 2013.
doi: 10.1007/978-1-62703-447-0 |
| 48 |
XIA P P , ZHANG L , LI F Z . Learning similarity with cosine similarity ensemble[J]. Inform Sci, 2015, 307, 39- 52.
doi: 10.1016/j.ins.2015.02.024 |
| 49 |
AZODI C B , PARDO J , VANBUREN R , et al. Transcriptome-based prediction of complex traits in maize[J]. Plant Cell, 2020, 32, 139- 151.
doi: 10.1105/tpc.19.00332 |
| 50 |
XIE Z , XU X , LI L , et al. Residual networks without pooling layers improve the accuracy of genomic predictions[J]. Theor Appl Genet, 2024, 137, 138.
doi: 10.1007/s00122-024-04649-2 |
| 51 |
AZODI C B , BOLGER E , MCCARREN A , et al. Benchmarking parametric and machine learning models for genomic prediction of complex traits[J]. G3 (Bethesda), 2019, 9, 3691- 3702.
doi: 10.1534/g3.119.400498 |
| 52 |
ZHANG H , XI Q , ZHANG F , et al. Application of deep learning in cancer prognosis prediction model[J]. Technol Cancer Res Treat, 2023, 22, 15330338231199287.
doi: 10.1177/15330338231199287 |
| 53 |
WANG P , LEHTI-SHIU M D , LOTRECK S , et al. Prediction of plant complex traits via integration of multi-omics data[J]. Nat Commun, 2024, 15, 6856.
doi: 10.1038/s41467-024-50701-6 |
| 54 |
CUI Y , LI R , LI G , et al. Hybrid breeding of rice via genomic selection[J]. Plant Biotechnol J, 2020, 18, 57- 67.
doi: 10.1111/pbi.13170 |
| 55 |
VABALAS A , GOWEN E , POLIAKOFF E , et al. Machine learning algorithm validation with a limited sample size[J]. PLoS One, 2019, 14, e0224365.
doi: 10.1371/journal.pone.0224365 |
| 56 |
VAN SMEDEN M , MOONS K G , DE GROOT J A , et al. Sample size for binary logistic prediction models: Beyond events per variable criteria[J]. Stat Methods Med Res, 2019, 28, 2455- 2474.
doi: 10.1177/0962280218784726 |
| 57 |
ALWOSHEEL A , VAN CRANENBURGH S , CHORUS C G . Is your dataset big enough? Sample size requirements when using artificial neural networks for discrete choice analysis[J]. J Choice Modell, 2018, 28, 167- 182.
doi: 10.1016/j.jocm.2018.07.002 |
| [1] | 付伟, 张冉, 丁虹, 臧素敏, 李祥龙, 褚素乔, 刘华格, 周荣艳. 太行鸡与坝上长尾鸡品种区分的分子标记筛选与鉴定[J]. 畜牧兽医学报, 2025, 56(8): 3761-3772. |
| [2] | 乔利英, 王万年, 张莉, 庞志旭, 张思颖, 李一凡, 刘文忠. 基于基因组标记对绵羊品种分类的机器学习方法研究[J]. 畜牧兽医学报, 2025, 56(5): 2157-2167. |
| [3] | 杨苗苗, 谢莉, 简宝怡, 罗超维, 谢卓君, 朱飘, 周天日, 李华, 向海. 利用机器学习构建和优化早期体尺性状对成年母鸡腹脂沉积的预测模型[J]. 畜牧兽医学报, 2025, 56(2): 548-558. |
| [4] | 阳文攀, 刘相杰, 罗冬香, 陈梦会, 谢瑛, 方跃鑫, 林婷燕, 李爱民, 李文静, 邓政, 丁能水. 基于芯片数据的长白猪繁殖性状基因组选择研究[J]. 畜牧兽医学报, 2025, 56(1): 213-221. |
| [5] | 窦腾飞, 吴嘉浩, 吴姿仪, 白利瑶, 李新建, 韩雪蕾, 乔瑞敏, 王克君, 杨峰, 王一宁, 李秀领. 基因组选择和选配技术在猪育种中的应用[J]. 畜牧兽医学报, 2024, 55(7): 2795-2808. |
| [6] | 王进部, 李佳, 任德明, 王立贤, 王立刚. 机器学习在畜禽基因组选择中的应用进展[J]. 畜牧兽医学报, 2024, 55(7): 2775-2785. |
| [7] | 吴华煊, 杜志强. 基因型特征提取方法影响基因组选择预测准确性的研究[J]. 畜牧兽医学报, 2024, 55(6): 2431-2440. |
| [8] | 李竟, 张元旭, 王泽昭, 陈燕, 徐凌洋, 张路培, 高雪, 高会江, 李俊雅, 朱波, 郭鹏. 机器学习全基因组选择研究进展[J]. 畜牧兽医学报, 2024, 55(6): 2281-2292. |
| [9] | 张元旭, 李竟, 王泽昭, 陈燕, 徐凌洋, 张路培, 高雪, 高会江, 李俊雅, 朱波, 郭鹏. 动物遗传评估软件研究进展[J]. 畜牧兽医学报, 2024, 55(5): 1827-1841. |
| [10] | 褚楚, 张静静, 丁磊, 樊懿楷, 包向男, 向世馨, 刘锐, 罗雪路, 任小丽, 李春芳, 刘文举, 王亮, 刘莉, 李永青, 江汉, 李委奇, 孙伟, 李喜和, 温万, 周佳敏, 张淑君. 基于中红外光谱的牛奶中三种氨基酸含量预测模型的建立及应用[J]. 畜牧兽医学报, 2023, 54(8): 3299-3312. |
| [11] | 丁纪强, 李庆贺, 张高猛, 李森, 郑麦青, 文杰, 赵桂苹. 比较机器学习等算法对肉鸡产蛋性状育种值估计的准确性[J]. 畜牧兽医学报, 2022, 53(5): 1364-1372. |
| [12] | 王琦, 朱迪, 王宇哲, 吴杰, 胡晓湘, 赵毅强. 全基因组SNP分型策略及基因组预测方法的研究进展[J]. 畜牧兽医学报, 2020, 51(2): 205-216. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||